
...your product has grown to multiple Development Teams. These teams all split off from a single original team with a stable velocity (see Notes on Velocity), but now each team has its own velocity. Each Development Team estimates its own work items. The Product Owner wants to establish a new velocity to create a Release Plan from the Product Backlog.
✥ ✥ ✥
You need to know the development velocity to establish release schedules and to estimate delivery ranges for Product Backlog Items (PBIs). In a single-team Scrum you can use that team’s velocity, but what do you do in a multi-team Scrum?
Each team has its own velocity, and there is no trivial way to average them together or to otherwise normalize them with each other. Just as there is a gestalt effect between team members that contributes to the high velocity of a team, so there are nonlinear influences between multiple coordinated teams that can either increase or decrease their collective effectiveness. Thus a multi-team Scrum has its own emergent velocity, and the Product Owner should use that collective velocity, rather than individual team velocities, when making the Release Plan.
During Sprint Planning, team members collectively estimate PBIs on the Product Backlog based on their intuition and past experience as a team. In a multi-team Scrum, each team can choose its own PBIs to take into a Sprint and can estimate them in isolation. If the team knows its velocity then it can forecast delivery of some set of PBIs. Even in a multiteam environment, an individual team could establish its velocity through experience over time. That would enable each team to select a set of PBIs that the team is very likely to complete at the end of the Sprint. The Product Owner can be confident in the possibility that the teams will meet their forecasts.
However, the Product Owner also predicts completion ranges for future releases and for specific PBIs. In a single-team environment the Product Owner can use the teams’ PBI estimates and the team’s velocity (as a range) for this calculation. However, multi-team efforts complicate the problem by raising the question of who estimates the PBIs and of how to calculate velocity.
Teams start estimating PBIs several Sprints before they come to the top of the Product Backlog. Assume that only a single team estimates each PBI. Either a team will implement the PBIs that it estimates, or some other team will. If teams implement only the PBIs that they themselves estimate, then it constrains the ownership of a PBI to teams long before development actually starts. There is a good chance that the PBIs will move up or down the Product Backlog in that interval. Consider that Team 1 estimates PBIs A, E, and F, and that Team 2 estimates PBIs B, C, and D. The PBIs have the order A - B - C - D - E - F as set by the Product Owner:
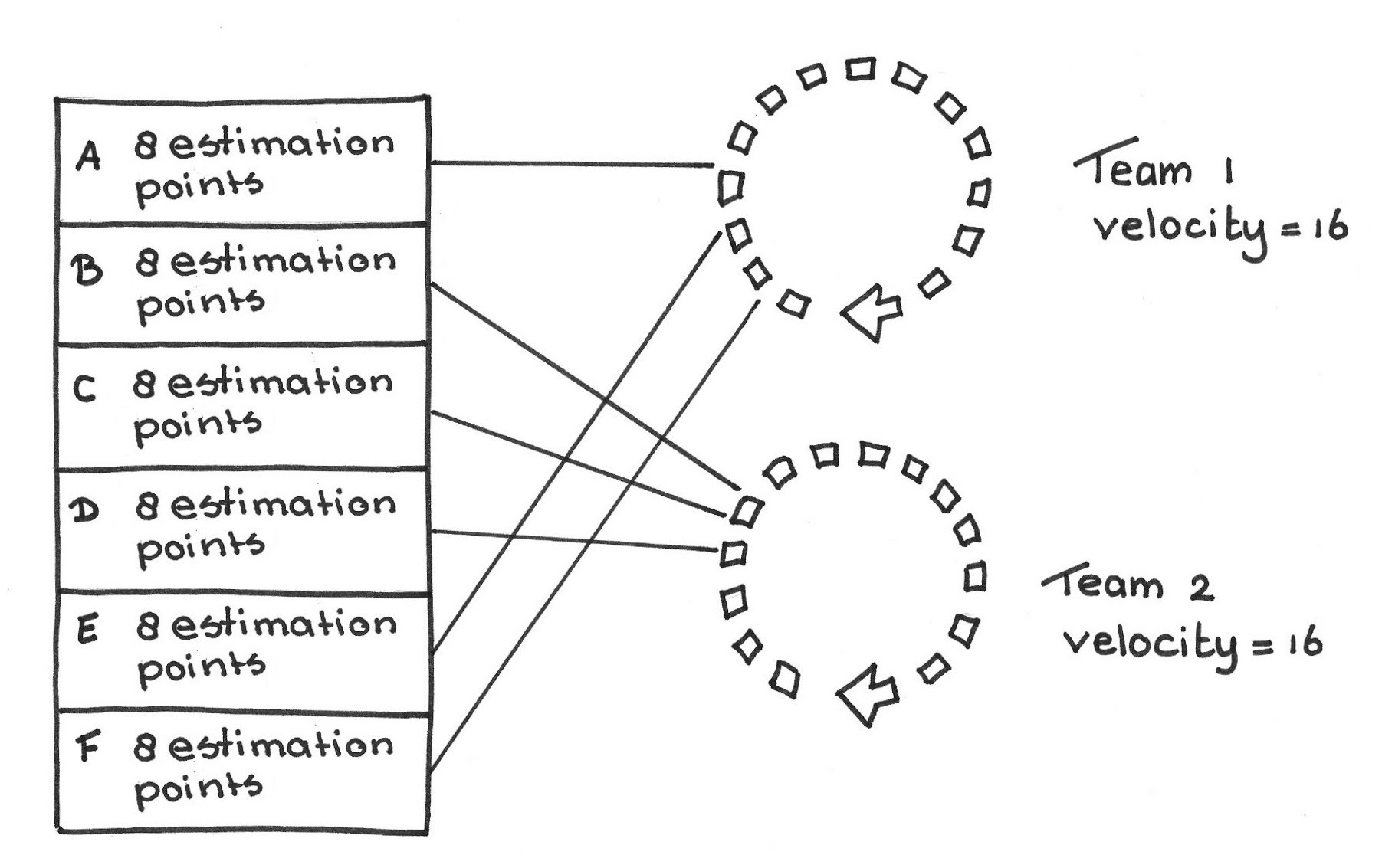
If both teams have a velocity of 20, and if teams must work on the items they themselves estimated, then it is impossible both for each team to fill its Sprint Backlog, and to honor the Product Owner’s desired ordering. If you combine this constraint with the additional constraints of dependencies between PBIs, or of marketing scheduling constraints, this becomes a hopelessly frustrating problem. Note that this is true even if you have cross-functional teams.
We can conclude that if only a single team estimates each PBI, then the estimate isn’t accurate enough for the Product Owner to calculate a range of release dates for it or for any PBI with a later delivery date—no matter who implements the PBI.
We could let multiple teams take turns estimating the PBI. Because teams use different baselines and have different talents, these numbers are likely to differ for different teams. You might imagine that you could make a running average over these numbers, but it doesn’t make sense to average a set of numbers from different scales. It’s like averaging miles-per-hour with kilometers-per-hour without any reference to the conversion factor between them. Note that this problem, too, arises even if you have cross-functional teams.
If, on the other hand, we reassign a PBI estimated by one team to another team to break it down into tasks for a Sprint, then the original estimate bears no correlation to the actual time or cost of the PBI. We should be concerned about that, because it was the original estimate that the Product Owner used to place this item in the Product Backlog. If we allow such reassignment for any PBI, then the PBI estimates are largely meaningless.
If there were some kind of conversion factor for velocities between teams, then we could normalize each PBI’s estimate by the ratio of the velocity of team that estimated the PBI to that of the team that will implement it. However, no such conversion factors exist: it makes no sense to compare team velocities because each team has its own baseline and range. Even if it were possible to compare them, the cost of implementing any particular PBI depends on the collective talents of the team that estimates those costs (because they anticipate implementing the PBI), and the difference in talents across teams can significantly skew such estimates. And what’s worse, and even more basic, a team does not feel committed to an estimate defined by someone else, even if each team is actually cross-functional.
When a team takes a PBI into a Sprint, it can throw away an estimate provided by another team and use its own estimate for its forecast. But that means that the estimates on the backlog are arbitrary except those going into the current Sprint.
And beyond this is the more obvious problem that if each team estimates “its own” PBIs based on its own baseline and estimation range, it is in general impossible to compare the cost of two items on a Product Backlog: it’s apples and oranges. You can’t compare velocities between teams, even if each team is cross-functional. This makes it impossible for the Product Owner to make an informed ordering of the Product Backlog based on relative cost of items, all other things being equal.
You could give each team its own Product Backlog, populating each one from the Chief Product Owner’s Product Backlog for the product. This might work if each team actually builds its own product with its own Value Stream and ROI (see Value and ROI). Then, it makes sense to have multiple Product Backlogs and to do away with the overarching one. But if all teams contribute their own part of an integrated product, this approach reduces to the problem described above, of assigning PBIs to teams too early:
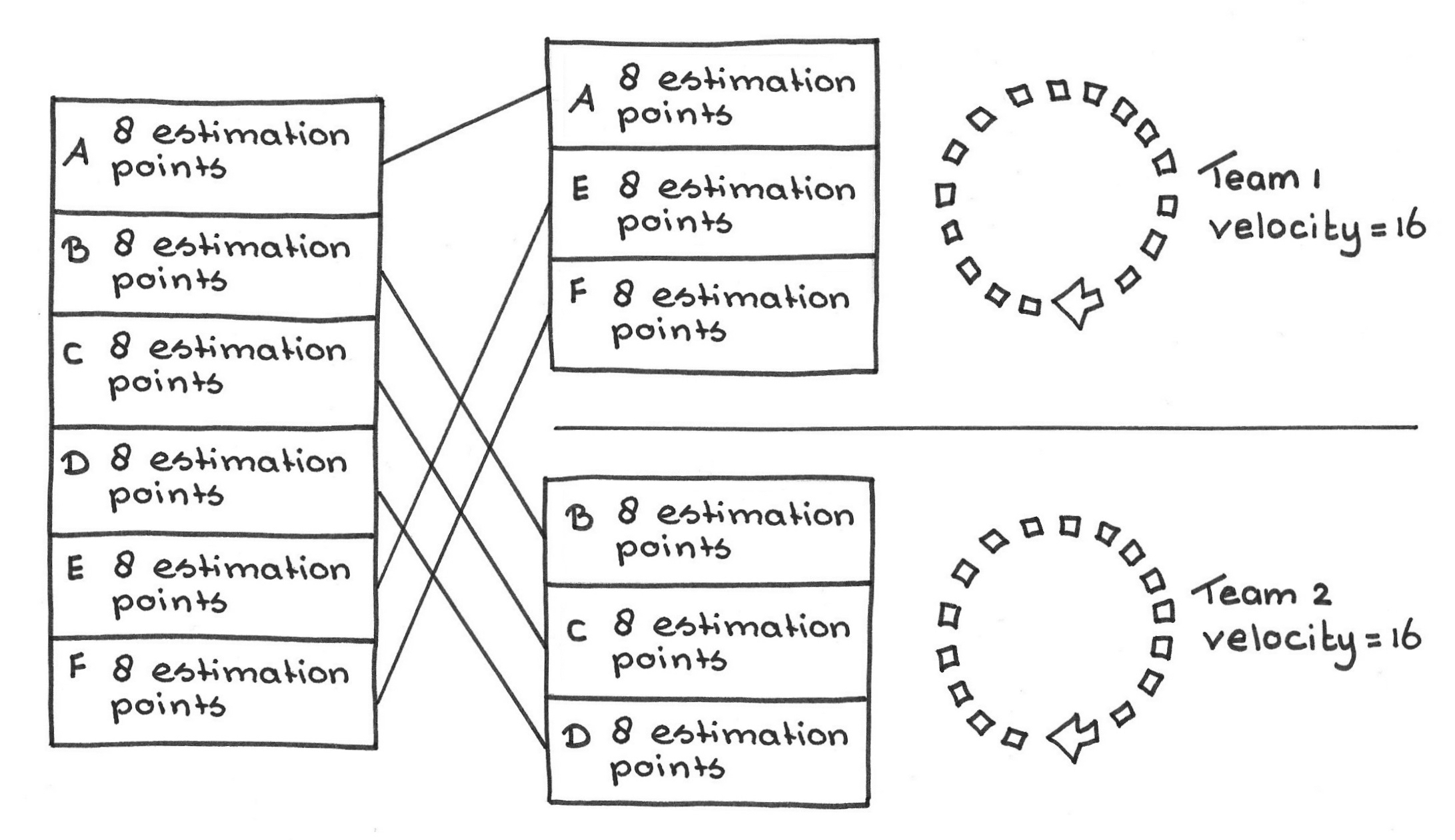
Furthermore, it complicates the Product Owner’s ability to reorder PBIs.
Therefore: Have all teams estimate all PBIs together, to extend the scope of consensus to all Development Team members. Derive the Estimation Points baseline and scale from all teams together. The aggregate velocity is simply the sum of all teams’ velocities together.
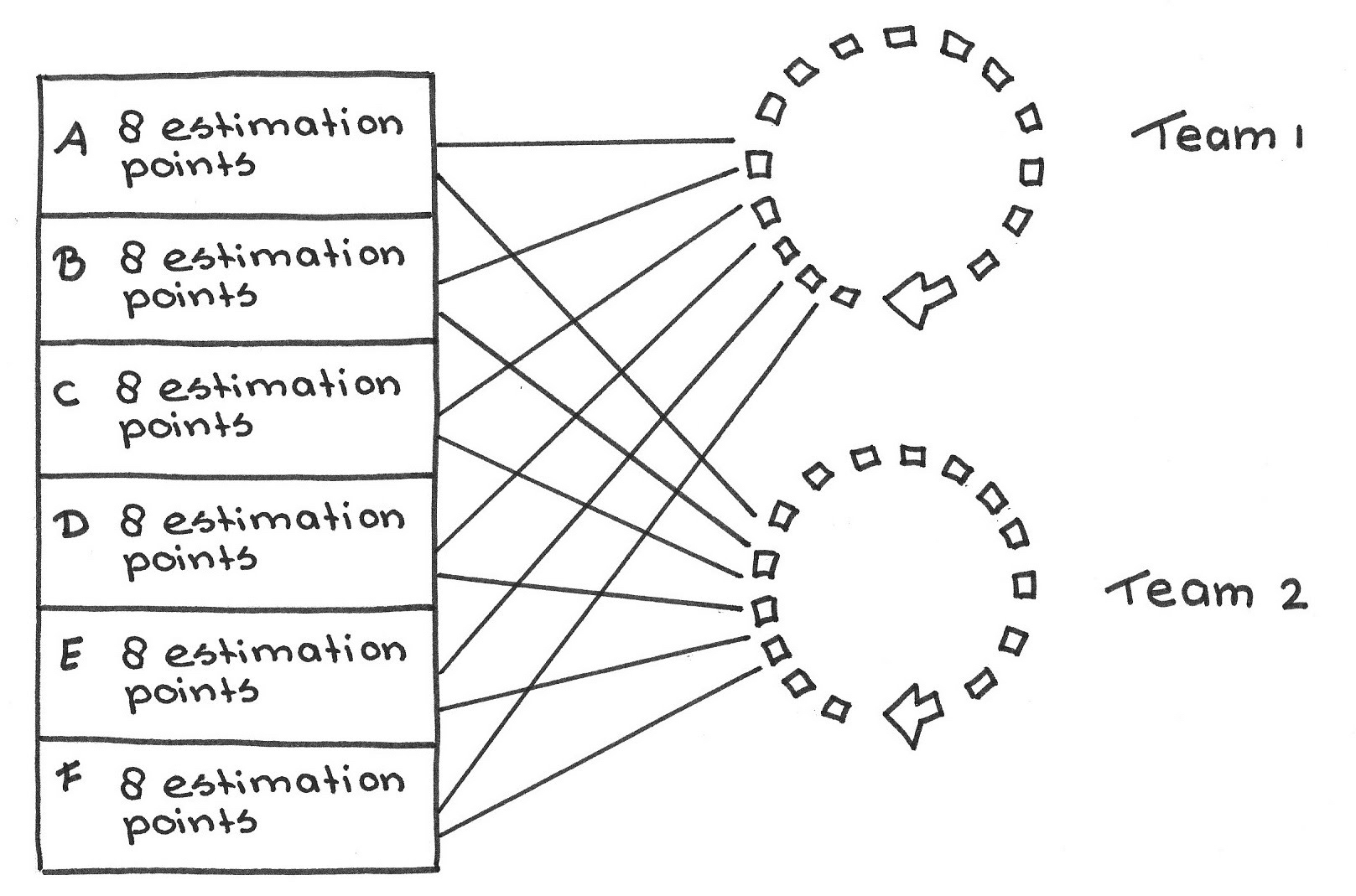
✥ ✥ ✥
This approach makes it possible for teams to estimate the Product Backlog in a way that does not limit how to assign any PBI to any team.
Each Development Team knows its own velocity and can properly size its Sprint Backlog for each Sprint.
There are many ways to implement this pattern. One might have each team estimate all PBIs in isolation before taking a second pass to reconcile the teams’ individual estimates. Alternatively, one can just let the teams reform themselves into estimation groups that are both cross-functional and which represent the constituency of all the Development Teams. An additional benefit from of this approach is that team members bring back knowledge of the Product Backlog—a “whole product purpose”—back to the team. The two mandatory building blocks of this pattern are that all teams contribute to the estimation of each PBI, and that all members of each Development Team participate in some estimation.
If you have specialized teams (e.g., Value Areas), you can use Specialized Velocities. The Specialized Velocities pattern more easily scales to a large number of teams than Aggregate Velocity does, while losing none of the “whole team” estimation one sacrifices when using the common practice of estimation by team representatives. It may also compensate for the impediment of multisite developments.
If all teams collectively estimate each PBI together, it could dilute the sense of each teams’ commitment to its velocity.
Reflect carefully when faced with the temptation to compare velocities among teams that one might feel this pattern facilitates. If you do conclude to compare teams, please reflect again.
Picture credits: Image Provided by PresenterMedia.com.